
To build an Orderbookkit Part 1, Supporting Stylus on Ethereum RISC-V Part 3, Wizard V2, Interview with Burak from Runtime Verification
18 February 2026

Hello everyone! Welcome to February.

Why did January go so quickly, was it something that you said? In this week:
To build an Orderbookkit part 1: Some background on the implementation and the design philosophy at work in the architecture of Orderbookkit, a one-click permissionless DEX for Arbitrum chains!
Supporting Stylus on RISC-V part 3: Supporting RISC-V execution on-chain on Arbitrum using the new risc-runner, and the practical application of it.
The Wizard V2: Building a Verifiable Delay Function proof generator and verifier for a randomness beacon using The Wizard. Part 1 as we flesh out the code.
Interview with Burak from Runtime Verification: We had the luxury of learning more about Burak’s journey through Web3 and Runtime Verification!
I should share that once upon a time we had a competition for survey respondents to receive a Supercat and a Knower NFT for sharing their feedback about our silly little newsletter. It’s been some time, and I’ll be awarding the winners soon. Thanks for your patience.
Want to build Arbitrum dApps even faster? Are you an AI user with Claude Code? Try this!

Made by the one and only Ben Greenberg (hummusonrails), it’s a MCP and setup toolkit that simplifies creating apps on Arbitrum quickly. Give it a try!
To recap, Stylus is a Arbitrum technology for building smart contracts in Rust, Typescript, Zig, and C. Stylus lets you build smart contracts that are 10-50x more gas effective and orders of magnitude more expressive than Solidity smart contracts.
To build an Orderbookkit Part 1, orderbook structure
Readers would know that we’ve been building an orderbook for Stylus for some time. Initially, I built a simple Uniswap V3-style tick orderbook with a queue for orders, but I didn’t feel it worked very well. There was a lot of slippage and price inefficiency, and storage access worked extremely poorly. After doing some research and discovery, I settled on this architecture:
A CLOB and RFQ hybrid orderbook
Orderbookkit is a CLOB and RFQ hybrid. It functions like a tree-based Central Limit Orderbook (CLOB) with some scaling for price amounts for orders outside the current spread (a custom defined window around the last fill price). Within the spread, a Request For Quote (RFQ) “sliplane” exists for off-chain or on-chain bundling and execution of orders.
Most orderbook operations are price discovery trades from market makers, which consist of tiny order creation then filling and cancellation. An entirely on-chain contract for this use-case is a poor fit, with order cancellation costing a transaction fee. This makes price discovery for market makers challenging. An upcoming Superposition property, Longtail Pro (powered by Espresso and also built with Stylus) takes a more naive approach on this, with a rolled up calldata and a native CLOB on a validium/state channel experience. This approach differs in its native execution flexibility at the expense of a more natural trading experience, and it makes a natural fit for our other application, 9lives. Which is growing a lot by the way, and keeping me VERY busy.
A RFQ hybrid architecture enables wide price swings from retail users by supporting instant execution with an on-chain fill using the tree skipping the RFQ functionality, but for minute trades within the spread, off-chain bundling and free cancellation with the RFQ system. This architecture also enables a ton of programmability options, including turning the RFQ engine into a liquidity sidecar for applications.
This liquidity sidecar overlayed on top of the RFQ engine supports several models including the 9lives’ Dynamic Pari-Mutuel (DPM) market model, the original version of 9lives. It empowers end users of Orderbookkit to choose their bundling and execution strategy, optionally filling liquidity and RFQ orders using cross-chain sources as opposed to local liquidity. It makes applications possible to be written where the orderbook interaction is an afterthought, making it possible to add selling to models that would not have had support traditionally.
This style of opt-in architecture to sidestep the market forces also means dApps could run almost entirely inside Orderbookkit. This, coupled with a recursive calldata pattern (as we’ve developed for Longtail Pro Passport and alluded to in this post, means dApps that run as an application-specific rollup, making gas-free applications possible on Arbitrum and on any Layer 3 chain for some types of interactions.
This fundamental rethinking as the orderbook not as the vehicle for matching orders but as the vehicle for execution itself is a fun rethinking of bundling applications themselves on-chain! So Orderbookkit could be considered a fun little rollup architecture depending on how its used.
On-chain execution with a new plugin architecture
Orderbookkit supports programmability with entirely new plugin architecture leveraging RISC-V. Hooks are built not using contracts that are registered ahead of time, but instead by delegatecalling into contracts that are “jailed” using a RISC-V simulator, or submitted natively based on the calldata provided by the user.
End users or the execution bundler elect to run these programs as guests, and the programs are running inside the contract’s space, so they have access to the storage layout of a high level bundler that’s run off-chain, or Orderbookkit’s order matching engine. This means the program can import the storage layout for Orderbookkit very simply, and use it themselves, without a series of onerous callbacks. The simulator enforces a pledge(2)-style syscall restriction on contracts executing alongside a higher level programmable interface inside the guest so these plugins have no escape from their intended purpose or have any potential for collateral damage. The intended purpose of this architecture is that we can develop plugins without needing to permission or register them ahead of time, a problem with existing hooks AMMs and platforms. This approach also works nicely with privacy and other addons by supporting a private order matching engine sidecar that feeds into the same space as everyone else, making opt-in privacy possible.
bobcat-sdk has been extended to support RISC-V as a backend, and it can be used this way without any friction.
Genetic programming market makers
One of the goals of the Orderbookkit project is supporting evolutionary programming for the plugins, optionally generated using a Proof of Work algorithm, like Anubis. I can’t say whether this will actually take place, but I imagine it would be fun. Maybe someday someone could write a scalable marketplace for proof of work algorithms that run instead of captchas.
This type of generated code enables a type of “cooperative orderbook”, with limited inherent value to the book. This enables a use-case I’m very passionate about, figuring out ways to do software timeline estimation within an organisation. Google and HP tried this, and failed due to liquidity issues. We can do better!
It’s simple: define a constraint and have your program automatically find the best fit. Evolutionary programs are better at functioning in resource constrained environments as an orchestration layer. The evolutionary programs can compose multiple programs together, including machine learning helpers for example. In our context, they’re very simple, but later, as we find ways to include more information points on-chain in a way they understand, they could do things like arbitrage spread when there’s enough liquidity elsewhere.
These are useful for our cooperative orderbook use-case by enabling us to take lots of information points and combine them together in ways that fit within the code constraints of the on-chain execution. In our prediction context inside organisations, this provides liquidity in a safe way. For everyone else, this fills the gap with missing liquidity amounts.
I envision a future where end user code searches an application space of user submitted programs that automatically execute in the context of the orderbook. A client, before placing an order in the sliplane, executes a number of programs in parallel before making the order to see if they can automatically fill themselves.
Contract interactions take place not with a series of external calls out or registrations of callbacks, but as a series of pipelining that took place automatically. I envision that this community search space of execution hooks that are opted into by the user’s client pay a small premium to the application developer, making it a landscape of programs that greedily consume liquidity chain-wide. It makes arbitrage not a function of professional market makers, but instead automatic programmers who’ve algorithmically identified opportunities that they pass down to end users. This rethinking that’s fundamental to Orderbookkit makes the exchange function less as a marketplace of orders but more as a octopus that constantly expands its web of liquidity sources, until it encapsulates everything on-chain.
Where’s the code?
I’m working on it! The risc-runner guest features has made its way to bobcat-sdk (missing heap allocation features right now however). There are a few more goals I want to have hit before opening this up to the world, namely:
Support for extending using stylus-sdk for the matching engine for basic accounting that the plugin layer doesn’t capture.
A bundler with multiple signature schemes supported, including the ed25519 precompile supported by Superposition.
Better testing.
Keep your eyes peeled for a part 2 on this. Thank you to Pruitt, Srinjoy, and the rest of the grant committee as well as the Arbitrum DAO (the sponsors of this project) for making this development possible! The code will also need to be audited. We’ll be discussing during our part 2 the implementation, pointing to how to leverage Orderbookkit in your project. We’ll be making use of this for 9lives to support a direct to market maker feature with the CLOB functionality disabled probably. For 9lives at least, this lets us scale our architecture without setup liquidity for now.
Supporting Stylus on Ethereum RISC-V Part 3
Part 3 of this series, the conclusion! A working running ELF-parsing example that runs on-chain, with a deployer available at a precompile address on Superposition and Arbitrum One. The code is bundled with Orderbookkit as it forms the basis of the plugin architecture. Let’s do some review:
An example program in Stylus RISC-V
Programs in RISC-V Stylus are like the following using bobcat-sdk:
#![no_std]
#![no_main]
use bobcat_sdk::prelude::*;
#[export_name = "_start"]
pub extern "C" fn _start() -> ! {
let args = read_args_safe!(args_len(), { 32 * 2 });
let (x, y) = read_words!(&args, 2);
write_result_word(&(x + y));
unsafe { exit_early(0) }
}This program simply multiplies two numbers together after reading them off the contract’s calldata. Behind the scenes, it uses environment calls that function almost identically to the classic WASM Stylus environment, though the way the program asks for memory will be different and require a custom allocator. stylus-sdk is very similar with its RISC-V form, and you can see that in the previous post.
Deployment
Deploying is like the following once this contract’s entrypoint is called, with a CREATEX-style hub. This runs inside the entrypoint to the loader:
let src = OurLzss::decompress_heap(
lzss::SliceReader::new(&read_args_vec(len)),
lzss::VecWriter::with_capacity(74 * 1024),
)
.unwrap();
check_elf(&src);
// Make the contract code:
let c = make_contract(src);
// Get the sender's nonce, and use that with CREATE2 so they get
// consistent deployment addresses on every chain they do this with:
let sender = msg_sender();
let slot_key = slot_map(&U::ZERO, &sender.into());
let user_nonce = storage_load(&slot_key);
// Bump their nonce preemptively:
storage_store(&slot_key, &(user_nonce + U::ONE));
// Now we deploy the implementation, with the user's address and nonce:
let salt_pre: [u8; 20 + 32] = concat_arrays!(sender, *user_nonce);
let (impl_addr, _, _) = create2_slice_pre_keccak256::<0>(&c, U::ZERO, &salt_pre);
if impl_addr == [0u8; 20] {
panic!("bad impl deployment");
}
// Now that we have the implementation, we can deploy the proxy contract
// that calls the loader:
let (proxy_addr, _, _) = create2_slice_pre_keccak256::<0>(
&make_proxy_loader(impl_addr, RUNNER_ADDR),
U::ZERO,
&salt_pre,
);
if proxy_addr == [0u8; 20] {
panic!("bad proxy deployment");
}
write_result_word(&proxy_addr.into());
0The deployment takes the contract and provides the code on-chain, with a prefix to cause the code loaded under normal circumstances to junk out with an INVALID operation. The runner skips this, after beginning its entry of the code.
#[unsafe(no_mangle)]
pub unsafe extern "C" fn user_entrypoint(len: usize) -> usize {
let args = read_args_vec(len);
let features = u16::from_be_bytes(args[20..22].try_into().unwrap());
libriscrunner::entry(args[..20].try_into().unwrap(), features, &args[22..]).unwrap()
}The entrypoint for the runner is to load feature flagging that was given for what should be supported, a restriction like pledge(2)/sysjail, where the host opts into restricting the syscall surface for the guest (or the rest of the program’s life if we’re being very literal).
It loads the entrypoint, the same way we discussed in the OCaml code. The code was loosely ported over, though Rust’s types for integer types made things a bit easier.

The code differs from the OCaml code in the last post since we could use the program headers instead of section headers (I had some tooling weirdness and couldn’t use this easily).
What’s next?
I’d like to support the Linux syscall surface and riscv64imgc so we can run Linux and OpenBSD on-chain. It should be achievable, and why not as a nice show and tell? It would be interesting to support an actual operating system or… Doom(?) on-chain. I’ve never done the latter (or the former).
The commercial imperative for me right now is to support Orderbookkit’s plugin system and competition solver, so this is a future task. With the Linux syscall interface and the rest of the extension, it should be possible to simulate most programming languages where WASM support is weak. Maybe an OCaml loader could come someday, so we can run the bytecode on-chain?
I’d like to also support a stylus-sdk trait inheritance extension of the runner for the ecall interface. This means that developers could build custom extensions to the plugin architecture easily. I would like developers to have access to a script interface similar to Bitcoin, where you can send a nice transaction that includes everything you want to do using this support. It should be achievable to have an interface that does this this way, something like this:
#[public]
impl IRiscRunner for MyToken {
type Error = permit::Error;
fn handle_ecall(
&mut self,
cpu: &mut Cpu,
sender: Address,
ecall_no: usize
) -> Result<(), Self::Error> {
// Do your handling here of anything custom!
}
}As a reminder, you can always sign up for Orderbookkit as it becomes generally available with a user interface at https://orderbookkit.xyz to see this in action.
The Wizard V2
The Wizard V2 came out recently! We’ve been following their journey for some time, and the newest release includes some major features we’ll highlight here:
Github integration! Clone repos to work on using the editor without any extra friction.
Deployment takes place entirely in the browser using the browser wallet. Deploy a contract using MetaMask or Rabby!
Multiple chains are supported with a simple RPC feature!
Editor user experience improvements including using multiple networks seamlessly.
These are great improvements for the major V2 release, and to test it out, I set out to create a new contract using only The Wizard.
Building a Verifiable Delay Function evaluator with The Wizard
We’re going to build a new contract, a Verifiable Delay Function (VDF) proof generator and evaluator!
A VDF is a problem that’s solved recursively in a way that can’t be parallelised, which functions well as a proxy for time and as a randomness beacon. The problem that’s solved recursively serves as a proxy for whether time has passed and as a randomness beacon, since the problem can’t be solved in parallel.
This is useful for the Superposition projects, since this way we can have randomness that’s not dependent on a randomness committee (with callbacks, a major programming hassle in my opinion) by having the resolving worker ask a service for a number. Our service will run this code constantly, and send it on request. Since our beacon is running on a non soft realtime system, it’s not perfect, but it’s a nice combination piece to be used with a random secret commitment from our infrastructure type of situation.
Setting the scene
To begin, we’ll figure out which VDF algorithm we want to implement. I chose the Pietrzak VDF algorithm depicted literally in Implementation Study of Cost-Effective Verification for Pietrzak’s Verifiable Delay Function in Ethereum Smart Contracts from 2024. There are two VDFs I’m aware of, the Wesolowski and Pietzrak VDFs, and as I understand, the latter’s prover is more efficient. The estimated gas savings in the paper we’re paraphrasing here provides us with a way to also say how much gas we’d save if we implemented the refined verification in Rust Stylus.
Ordinarily, algorithms like this would be implemented using the GNU Multiple Precision Arithmetic (GMP) library, though for our learning purposes we’ll be implementing it using Ruint for portability reasons. I imagine that GMP could be used in the WASM context, but I have no idea how. Is it even important since you wouldn’t net any performance benefits? Maybe someone can implement a “precompile” with a light scripting language for pipelined gmp operations or simply expose each function this way, I don’t know the impact on codesize for this.
We need 2048 bit numbers using Ruint (the size used in the paper), and we’ll be avoiding optimisations including Montgomery modular multiplication.
Implementing the evaluation algorithm

We’ll be evaluating all code using The Wizard. The evaluation algorithm is pretty simple. It’s y = x^(2^T) % T. The evaluation algorithm is the time consuming delay function code that we need to use to generate the proof. It’s the crux of the algorithm, we need it to consume time, since its applied recursively without known parallelism.1 The maximum size of the input we’ll use for U is the largest Ethereum word we can use, so we don’t need to adjust the number here to avoid overflowing.
The inputs to this function and the rest are (paraphrased from the paper, almost literally copied):
x: The input for the VDF evaluation.N: The modulus (an RSA modulusN = p * q), wherepandqare large primes.T: The time delay parameter, where
T = 2^taufor some tau (τ).tau: The number of iterations needed for the proof. The higher this is, the greater the amount of time we’d have to spend.
y: The output value, computed asy = x^(2^T) mod N. Aka, the evaluation function we just showed off.
Implementing the proof generation algorithm
Let’s implement the proof generation. This is the algorithm in the paper:

What this essentially does is split the evaluation algorithm’s chain in half (the halving protocol). The implementation looks like this:
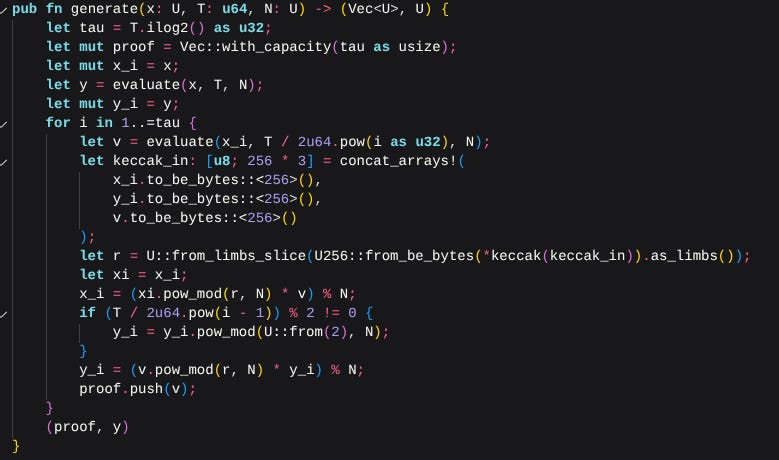
This function is pretty ugly and leaves much to be desired with its performance and readability characteristics. The implementation here makes use of variables instead of vectors. While taking T, it will use a 64-bit number here. The reason is that T is the amount of time that needs to pass, and we want to tolerate that number being quite high. Though the wasm32 machine natively doesn’t support words of this size, it supports 64-bit operations. We’ll be pushing the higher end of the 64-bit numbers for our time spent here.
Implementing the refined verification algorithm
This ability to skip time features in the refined algorithm:

Which looks like this in The Wizard:
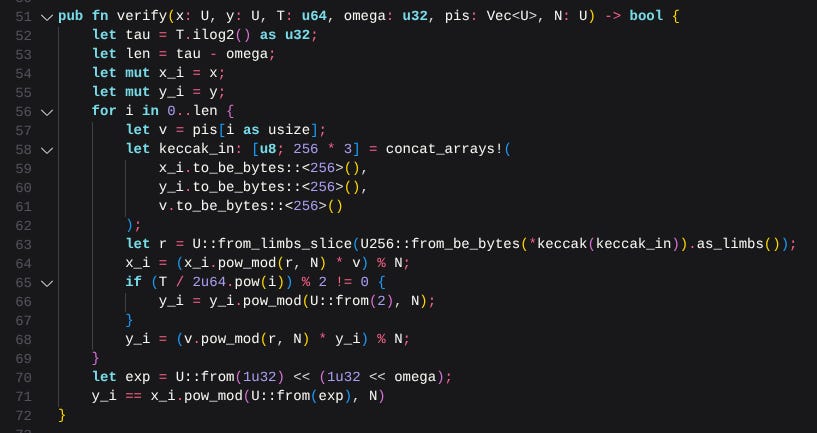
Since the protocol works with halving to verify the generated proof, the larger the time parameter, the larger the proof size (and therefore the calldata we send on-chain). Since we can’t afford to have a situation where this is the case, Pietrzak implemented a way to skip an amount of time in the proof. For this reason, we avoid calculating when someone enforces a time skip parameter to avoid wasteful computation.
We do bitshifting math instead of performing 2 to the power of 2 here, to save a few cycles. We use pow_mod to avoid overflowing the number. Special shoutout to Claude for doublechecking my work, Erik of Fluidity Labs for a review, and Tolga for fixing problems I ran into when using The Wizard!
In a part 2, we’ll review this code and test it properly, and do a formal comparison to the paper to understand the gas consumption differences!
Interview with Burak from Runtime Verification

Runtime Verification are working on extending their Skribe tool to support Stylus! We’ve recently been collaborating with them as they have their tool work on the 9lives repo. I can tell that Burak is a heavy dev based on the modifications they’ve been making to the 9lives repo to support Skribe.
Who are you, and what do you do?
I’m a Research Engineer at Runtime Verification. My focus is on building formal verification and property-based testing tools for blockchains, using the K framework and formal semantics as the foundation. In practice, that means trying to make strong correctness guarantees usable by everyday smart contract developers.
Most of my work revolves around Rust and WebAssembly. Recently, I’ve been working on Skribe, a property-based testing tool for Arbitrum Stylus. Skribe is intended to be the Arbitrum equivalent of Foundry’s fuzz testing for Solidity, with support for both Rust and Solidity contracts.
What web3 ecosystems have you worked in?
Most of my work has been on WASM-based blockchains. So far, that includes MultiversX, Stellar, and now Arbitrum. Across all three, I’ve worked on similar problems: building formal verification and property-based testing tools for smart contracts.
For MultiversX, we developed a tool called Kasmer, which we used for the formal verification of real-world contracts such as multisigs and AMMs. For Stellar, we built Komet, which we actively use in Stellar smart contract audits for property-based testing. More recently, I’ve been working on Skribe for Arbitrum Stylus.
What are your impressions of working with Stylus?
Rust + WASM + EVM is a genuinely exciting combination. On the EVM side, there is already a mature ecosystem that has been built up over many years. Rust complements that with a strong type system, good performance, and more explicit control over memory and correctness, things I personally care about a lot.
From that perspective, Rust fits smart contract development well: it is type-safe, predictable, and efficient. Its popularity and wide adoption can also make Arbitrum more appealing to a broader developer audience. Another nice upside is that existing general-purpose Rust libraries can potentially find their way into smart contracts, which opens the door to reusing well-tested building blocks.
What software do you use?
We mainly work with the K Framework, a formal semantics framework developed at Runtime Verification. With K, we define the semantics of a programming language in the K language, and from that definition the framework gives us, almost automatically, an interpreter and a symbolic execution engine. On top of these, we build formal verification and property-based testing tools.
Up to this point, this might sound quite theoretical and a bit intimidating. In practice, though, our focus is on using this foundation to build practical tools that regular developers can actually use. We take the underlying mathematical foundation and turn it into accessible, developer-facing tooling, rather than something that only formal methods experts interact with.
As I mentioned earlier, we work across multiple blockchain ecosystems. What makes this feasible is that semantics written in K are reusable, modular, and extensible. For example, the same WASM semantics can be shared across MultiversX, Stellar, and Stylus, instead of reimplementing everything from scratch each time. As a result, improvements made for one project often carry over to others, which lets us move faster and build on accumulated work rather than starting over for each ecosystem.
What hardware do you use?
Most of my time on a computer is spent compiling code or running large test suites. Because of that, I use a Linux desktop with the fastest CPU I can reasonably get and plenty of RAM.
CPU performance matters a lot for compilation and symbolic execution workloads, and having enough memory helps keep things smooth when running multiple tests or analyses in parallel. Beyond that, I honestly don’t care much about the rest of the hardware, and I’m not even sure what kind of GPU is in the machine.
How can we get in touch with you?
You can reach me via Telegram (bbyalcinkaya). For broader questions or collaborations, getting in touch through Runtime Verification (https://runtimeverification.com/) is also a good option.
What’s a piece of advice you’d give someone new to web3?
I’d suggest starting with a security mindset from day one. In web3, mistakes tend to be permanent and expensive, so correctness matters much more than in many other areas of software development.
It’s worth looking at the methods and practices used in the industry to write safer and more reliable smart contracts: things like testing, fuzzing, audits, and, where possible, formal verification. Even if you don’t use all of these tools yourself at the beginning, understanding why they are used helps shape how you design and reason about your code.
Just as important as doing formal verification is adopting a formal verification mindset. Thinking explicitly about the properties and invariants of the system you are building, and trying to express them as precisely as possible—even mathematically—can be very valuable, regardless of which tools you end up using.
Runtime Verification can be contacted via their website. Burak can be connected with via Linkedin. He can also be followed via Github!
Stylus Saturdays is brought to you by… the Arbitrum DAO! With a grant from the Fund the Stylus Sprint program. You can learn more about Arbitrum grants here: https://arbitrum.foundation/grants
Follow me on X: @baygeeth and on Farcaster!
I develop Superposition, a defi-first chain that pays you to use it. You can check our ecosystem of dapps at https://superposition.so

Using the Montgomery form here could be a major performance improvement, which is important, since we’re using the same Rust code in the production application. I don’t know and need to learn more about this. The version that Superposition ships may use this optimisation.