
Supporting Stylus on RISC-V (part 1), Interview with Levan (blockcraft3r)
Stylus Saturdays, 17th June 2025

Hey everyone! Bayge here. This week:
🕹️ Supporting Stylus on RISC-V: I’m pleased to share I’ve written a simulator for RISC-V with Ethereum environment calls, and am supporting the Stylus SDK with it for a few things! This post will share a link to the simulator without the patched SDK, which I’ll release in a part 2.
🍲 Interview with Levan, Elite hackathon winner.
I’m super excited to announce that we’re collaborating with LearnWeb3 as a Stylus resource! LearnWeb3 is an educational platform to learn development. More to come soon.
Read on, and as always, if you have any feedback, you can share it here:

To recap, Stylus is a Arbitrum technology for building smart contracts in Rust, Zig, C, and Go. Stylus lets you build smart contracts that are 10-50x more gas effective than Solidity smart contracts, with a much broader range of expressiveness from these other languages! Contracts can be written with no loss of interopability with Solidity!
Click here to learn more: https://arbitrum.io/stylus
You can get started very quickly at https://stylusup.sh
Congratulations to the team for releasing 0.9.0! 0.9.0 includes several meaningful improvements including trait based inheritance! I can’t wait to play with this.
1) Stylus on RISC-V (32IM) Part 1

You may have seen the news recently with Vitalik mentioning wanting to simulate RISC-V on-chain, in lieu of (and perhaps alongside or interpreting) the EVM bytecode format of today. The goal I assume is that it’s useful for completed proving with ZK tools, maybe motivated by the research of RISC Zero and the rest of the ecosystem researching proving there. I was discouraged to see that he used ChatGPT to suggest that Rust smart contracts are ugly, we know from experience here in the Stylus ecosystem that that’s not necessarily the case!
To recap how Stylus works: WASM is sent on-chain, nodes download the code, then the nodes “warm” them up (or “bake” them), and the programs are converted to native code and stored. Certain operations are unavailable, including floating points, any threading extensions, etc. I noticed that WASM’s newest spec was just ratified, and it includes operations involving scalar word and vector operations, which is quite exciting. These translate nicely into the native environment alongside the memory model, which is already familiar to most programmers outside of the Ethereum world.
I don’t believe that there is any advantage to a particular execution environment when it comes to performance between WASM and RISC-V, but the former has a storied history of execution in sandboxed and JIT’d environments (the browser), while the latter is preferred in the embedded context. With this perspective, it should be possible to build a interpreter on-chain that interprets RISC-V without any significant cost, except perhaps the storage and the loading of the executables. It should be possible to have near-native performance of execution of what you might otherwise see of a full rewrite of some node running software, since a native executable is simulating it anyway. It should be possible to reuse the existing SDK and toolchain to generate the code.
The full goal:
Get a RISC-V interpreter interpreting RV32IM running unprivileged code code deployed on-chain without any trap handling features. Get a program loading model in somehow, perhaps involving reading from a deployed contract with a junk preamble that gets skipped. Test that it can simulate the contract, using 9lives’ stylus-interpreter and some spooky stuff. I chose this variant because of the “riscv32im-risc0-zkvm-elf” target that Rust makes available, which is used by Risc Zero’s toolchain, which is a tweaked environment that provides some custom accelerators for some areas of cryptography. Though our end goal overtly won’t be to use their stack for proving and verifying (simply to use riscv32im on-chain), we’ll find out in this article how feasible this will be to use! This is an exploration, and this possibility could unlock some future coprocessing usecases. In this post, we’ll only be simulating it locally to see if our concept works.
Add some operations to the interpreter that use the available exports that we’ve grown accustomed to. These include storage accesses. Keep it simple for now to validate the concept works.
Release a contract somehow that transparently uses any RISC-V code when it’s called into the same way as you might a WASM contract.
Maybe even figure out how to prove what’s happened by receiving a receipt from a Stylus program? Risc Zero’s prover stack gives you a STARK that you can use to verify the execution of the contract on-chain. It might be redundant to do so, since we’re executing on-chain, but maybe there are other possibilities out there that could be expanded on if that’s possible? Maybe ZK coprocessing an off-chain Stylus contract that leverages some permissioned local offerings or something similar? Though, the focus of this will be using the Stylus SDK with the ISA and an interpreter, on-chain.
So, in this part 1, we’ll be building a OCaml-based simulator of RISC-V 32IM to experiment with our approach, and showing off how to load in the SDK for some EVM native numbers before later completing the SDK to use RISC-V fully in a later post. I have some development done there, but I don’t feel complete about it yet and want to release something since it’s been a while!
Setting up a project
First, let’s compile a simple hello world program, but import the Stylus SDK and use a type exported from it:
// src/main.rs
#![no_std]
#![no_main]
#[panic_handler]
fn panic(info: &core::panic::PanicInfo) -> ! {
unimplemented!()
}
pub extern "C" fn main() -> ! {
loop {}
}Since we don’t have a way to return things, we need to hole out the return type for our exported main symbol. That’s what we do here. I set some other things:
// .cargo/config.toml
[build]
target = "riscv32im-unknown-none-elf"
rustflags = ["-C","panic=abort"]// Cargo.toml
[package]
name = "risc-hello-world"
version = "0.1.0"
edition = "2021"
[profile.release]
codegen-units = 1
opt-level = "z"
strip = false
lto = true
debug = false
rpath = false
debug-assertions = false
incremental = falseGreat. Seems familiar? Now, to use stylus-sdk in its basic use. I pulled emballoc off the net without thinking much about it, because I gathered from its description that it would be suitable for our target. I downloaded stylus-sdk, alloy-primitives, and disabled the default features. I went to compile and we hit our first roadblock:
error[E0432]: unresolved import `alloc::sync`
--> /home/user/.cargo/registry/src/index.crates.io-6f17d22bba15001f/const-hex-1.14.0/src/traits.rs:14:5
|
14 | sync::Arc,
| ^^^^ could not find `sync` in `alloc`
|
note: found an item that was configured out
--> /home/user/.rustup/toolchains/1.83-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/alloc/src/lib.rs:246:9
|
246 | pub mod sync;
| ^^^^
note: the item is gated here
--> /home/user/.rustup/toolchains/1.83-x86_64-unknown-linux-gnu/lib/rustlib/src/rust/library/alloc/src/lib.rs:245:1
|
245 | #[cfg(all(not(no_rc), not(no_sync), target_has_atomic = "ptr"))]
| ^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^What now? I wonder what the context of this dependency is? I was under the impression const-hex was simple (just for having hex strings decoded at constant time), but perhaps something else is going on here. Let’s dip deeper. I disabled the default features, which included “alloc”, since apparently that’s implicitly enabled. I was hoping that would feature flag out alloc, but I was mistaken. Ouch, it seems that alloy-primitives has a hard dependency on const-hex having alloc enabled.
Let’s try downloading alloy-core, then patching its dependency on const-hex by removing the setting of the alloc flag:
error[E0425]: cannot find function `serialize` in crate `hex`
--> crates/primitives/src/bytes/serde.rs:10:18
|
10 | hex::serialize(self, serializer)
| ^^^^^^^^^ help: a function with a similar name exists: `deserialize`
|
::: /home/user/.cargo/registry/src/index.crates.io-6f17d22bba15001f/const-hex-1.14.0/src/serde.rs:63:1
|
63 | / pub fn deserialize<'de, D, T>(deserializer: D) -> Result<T, D::Error>
64 | | where
65 | | D: Deserializer<'de>,
66 | | T: FromHex,
67 | | <T as FromHex>::Error: fmt::Display,
| |________________________________________- similarly named function `deserialize` defined here
|
note: found an item that was configured out
--> /home/user/.cargo/registry/src/index.crates.io-6f17d22bba15001f/const-hex-1.14.0/src/lib.rs:124:31Looks like we have a battle ahead of us on this. What business does const-hex have with atomic reference counting anyway? I wonder if we can find a constant time hex that does things in a no-std environment comfortably without the alloc dependency. I found https://docs.rs/const-decoder/latest/const_decoder/… Wow, this is hard basket. Maybe another approach is needed? Why does const-hex need Arc? Answer: for a trait it implements. Perhaps we can take it out of the picture somehow. It looks like const-hex has the alloc flag for the Arc dependency, among other things. Removing the Arc FromHex impl is definitely a lot easier!
Moving along, we run into similar issues. dyn-clone, lazy-static, they all have in common a alloc::sync dependency! It seems like the complete availability of alloc (albeit, for the rest of the variants) is a hot and ongoing topic, from a cursory search: https://github.com/rust-lang/rust/issues/140042 and https://github.com/rust-lang/rust/issues/135376#issuecomment-2593558310. I learned today that MIPS is also supported as a Risc0 ZKEVM target.
I soldiered on, going full hatchetman on everything involving alloc::sync, atomic, etc. I needed to set up critical-section with portable-atomic to support some libraries, and I needed to stub out the behaviour with the critical section so my simulator wouldn’t need to implement any CSRs for this functionality.
Looks like we’re in business!
Compiling stylus-core v0.8.3 (/home/user/Downloads/stylus-sdk-rs/stylus-core)
Compiling stylus-sdk v0.8.3
Compiling risc-hello-world v0.1.0 (/home/user/Documents/markov-geist-research/risc-hello-world)
Finished `dev` profile [unoptimized + debuginfo] target(s) in 1.07s
% I had to unfortunately patch a few dependencies for this to work..
Interpreting with Spike
To interpret RISC-V using Spike, the preferred simulator for RISC-V I gather, aside from Qemu, I largely followed the instructions of https://riscv.epcc.ed.ac.uk/documentation/how-to/install-spike/, breaking from the instructions to alias gcc/ld/etc to a higher priority with my PATH, to reuse it for compilation.
I needed to install the RISC-V ELF toolchain to get the libraries and tools needed for compilation, as we need to sidestep Rust’s standard linker. On my somewhat space challenged laptop, this was a battle, because I wanted to install the toolchain at /opt/riscv per the instructions, but I was unable to, having to settle for my home instead. The tools we’d used alluded to the idea of a RISCV location, so this is exciting, as its the first time that we’re installing the actual build toolchain with GCC!
Warning: git clone takes around 6.65 GB of disk and download size
Boy did I really feel this one. It’s not like I torrent (much). I should’ve bought a Framework laptop with the disk size cranked up higher than my simple El Cheapo Thinkpad. My computer spent at least a few hours compiling everything. I built the newlib version of the RISC-V toolchain (./configure --with-arch=rv32imac --with-abi=ilp32 --prefix=$HOME/riscv --host x86_64-unknown-linux-gnu). I then followed the instructions in the repo, and compiled and set up Spike’s simulator.
I ran Spike with spike --isa=rv32im target/riscv32im-unknown-none-elf/debug/risc-hello-world. Running it seems to start things without any issue, and control-c dumps me into a prompt, which I assume is the debugging experience. Running with “r” kicks us off with spam about illegal accesses, so this is the wrong approach it seems. I went back to the drawing board, and changed the linker that Rust uses to use the one that I got earlier:
[build]
target = "riscv32im-unknown-none-elf"
rustflags = [
"-C","panic=abort",
"-C","link-arg=-march=rv32im",
"-C","link-arg=-mabi=ilp32",
"-C", "link-arg=--entry=_start"
]
[target.riscv32im-unknown-none-elf]
linker = "riscv64-unknown-elf-gcc"This lets us compile to ELF, instead of the GNU format that we were using. I also had to point the linker to the location of a object file it couldn’t find (I must’ve made a mistake in the past or something with the prefix argument). Success:
spike --isa RV32IM target/riscv32im-unknown-none-elf/debug/risc-hello-worldI couldn’t find a way to get the symbols exported that I wanted to communicate with Spike though. I think the linker or Rust must’ve been optimising it out. But for our purposes, this seems to work! I played around a little to use different operations to see the impact to verify things were running fine, and they were. I set the layout of the ELF to be the following:
MEMORY {
RAM : ORIGIN = 0x80000000, LENGTH = 128M
}
ENTRY(_start)
SECTIONS {
.text : {
*(.text.entry)
*(.text .text.*)
} > RAM
.rodata : {
*(.rodata .rodata.*)
} > RAM
.data : {
*(.data .data.*)
} > RAM
.bss : {
*(.bss .bss.*)
} > RAM
}We define a trap handler for Spike to jump into when we have a trap situation (as is the normal behaviour with RISC-V under most circumstances), and the _start section, which we’ll use to define as the program entrypoint, as well as define some program-wide NOP mutex functions that we need to be downstream users of Alloy-dependent atomics code. At this point, I needed to rip out emballoc, since I found it was spincycling when we weren’t setting the critical region in a way that it wanted. This is a simple bump allocator we’ll be using (ignore the warning messages when you use this, I’ll fix that eventually):
use core::{
alloc::{GlobalAlloc, Layout},
ptr::null_mut,
};
pub struct SimpleAlloc {
heap_start: usize,
heap_end: usize,
next: core::cell::UnsafeCell<usize>,
}
unsafe impl Sync for SimpleAlloc {}
impl SimpleAlloc {
pub const fn new() -> Self {
Self {
heap_start: 0,
heap_end: 0,
next: core::cell::UnsafeCell::new(0),
}
}
pub fn init(&self, start: usize, size: usize) {
unsafe {
let self_mut = self as *const Self as *mut Self;
(*self_mut).heap_start = start;
(*self_mut).heap_end = start + size;
*(*self_mut).next.get() = start;
}
}
}
unsafe impl GlobalAlloc for SimpleAlloc {
unsafe fn alloc(&self, layout: Layout) -> *mut u8 {
let next_ptr = self.next.get();
let mut next = *next_ptr;
let align = layout.align();
next = (next + align - 1) & !(align - 1);
if next + layout.size() > self.heap_end {
return null_mut();
}
*next_ptr = next + layout.size();
next as *mut u8
}
unsafe fn dealloc(&self, _ptr: *mut u8, _layout: Layout) {}
}
At this point, our dependencies look like this from my off-screen exploration, mostly setting feature flags for our dependencies:
[package]
name = "risc-hello-world"
version = "0.1.0"
edition = "2021"
[dependencies]
stylus-sdk = { version = "0.8.3", default-features = false }
stylus-core = { version = "0.8.3", default-features = false }
alloy-primitives = { version = "=0.8.20", default-features = false }
const-hex = { version = "1.14.0", default-features = false }
lazy_static = { version = "1.5.0", default-features = false, features = ["spin_no_std"] }
dyn-clone = { version = "1.0.19" }
bytes = { version = "1.10.1", default-features = false, features = ["extra-platforms"] }
portable-atomic = { version = "1.11.0", default-features = false, features = ["critical-section"] }
critical-section = { version = "1.2.0", default-features = false }
spin = { version = "0.9.8", default-features = false, features = ["portable_atomic"] }
[patch.crates-io]
const-hex = { path = "/home/user/Downloads/const-hex" }
dyn-clone = { path = "/home/user/Downloads/dyn-clone" }
stylus-core = { path = "/home/user/Downloads/stylus-sdk-rs/stylus-core" }I needed to patch these repos to remove atomic code and have them downloaded locally. I needed to also ask certain packages to use portable-atomic where it could, and then I imported critical-section, which lets us guard the program as it runs in a mutex to implement some synchronisation features without using privileged instructions (or RISC-V CSRs).
I implemented some code like below to set up the allocator:
#![no_std]
#![no_main]
#[global_allocator]
static ALLOCATOR: emballoc::Allocator<4096> = emballoc::Allocator::new();
extern crate alloc;
use stylus_sdk::alloy_primitives::U256;
#[no_mangle]
extern "C" fn _exit(_code: i32) -> ! {
loop {}
}
#[panic_handler]
fn panic(_: &core::panic::PanicInfo) -> ! {
unimplemented!()
}
struct SingleCoreCriticalSection;
critical_section::set_impl!(SingleCoreCriticalSection);
unsafe impl critical_section::Impl for SingleCoreCriticalSection {
unsafe fn acquire() {}
unsafe fn release(_token: ()) {}
}
#[export_name = "_start"]
pub extern "C" fn _start() -> ! {
unsafe {
let heap_start = HEAP.as_mut_ptr() as usize;
let heap_len = HEAP.len();
ALLOCATOR.init(heap_start, heap_len);
}
let x = u32::from_le_bytes(
(U256::from(123) + U256::from(456)).to_le_bytes::<32>()[..4]
.try_into()
.unwrap(),
);
unsafe {
core::arch::asm!("mv a0, {}", in(reg) x);
}
loop {}
}
#[export_name = "__trap_vector"]
extern "C" fn trap_vector() -> ! {
loop {}
}This compiled and ran fine inside Spike! I could verify that the a0 register was set with the results of the 123 + 456 integer sum.
Building the simulator
Now that we’ve verified we can compile Rust programs and run them in Spike, it’s time to write a simulator that interprets RISC-V code of the 32-bit IM variation.
First, for this post, I’ll implement it in OCaml since I like the typing features. I’m a huge fan of OCaml for its code generation to S-expressions and recursive datatypes (including GADTs among other things), which we’ll use as our discussion and intermediate language. Always reimplement your code twice if you can, especially if the need is to blackbox your understanding, to build a weak proof of your concept and your understanding (this is why we build specs and multiple clients and teams). For the OCaml implementation we’ll be building an intermediate representation stage that will simplify development and debugging, at the expense of performance, which we’ll term the lifted stage.
All of our code will of course be supporting loading binaries using the ELF format, which I hope we can safely encode as a EVM contract on-chain without being gated by the 24kb contract deployment restriction. If we have to, we should have enough memory inside the Stylus execution environment to do multiple copies of a program which we reconstruct (imagine yourself uploading a Solana program, now reverse that). In practice on-chain, each contract will have a stub infront to prevent loading by normal EVM contracts, Vyper standard library when you use a blueprint style.
Our interpreter will of course be a single core, and will support the entirety of the IM variant. We will not be implementing any accelerators or coprocessors, though I would like to support Risc Zero’s additions in the future if this becomes a thing that becomes useful to others, or maybe my team makes some use of it as a ZK bridge for our Longtail Pro validium. I thought about this a little, and perhaps we could get there by building some application specific sequencing with this concept. When we implement the calling interface for chatting with our on-chain state with environment calls, we’ll use the calling conventions in the RISC-V SBI (Supervisor Binary Interface). Everything will run in single hardware thread from the running code’s perspective, with no multiplexing or anything similar onto the underlying OS environment, for obvious reasons. We’ll use Spike’s convention of setting the registers at the beginning of the simulation to zero. Reiterating: for now, we’ll implement EVM operations as ecalls without trap handling and mset/etc (we’ll simply write to memory for our example).
Implementing C bindings to binutils
ELF is of course the object loading format we use daily. ELF is made up of sections, with a few having predefined purposes, including a data, junk, and executable section. We won’t be reading from program headers since I’ve had so many issues linking to libelf (which would’ve been preferable here). Program headers are a simpler way to lay out the program in memory, and the sections are more information for linkers and development tools. In our first revision OCaml simulator, we’ll be using binutils C bindings to read sections to get these. This is due to linking issues I had with libelf on my computer:
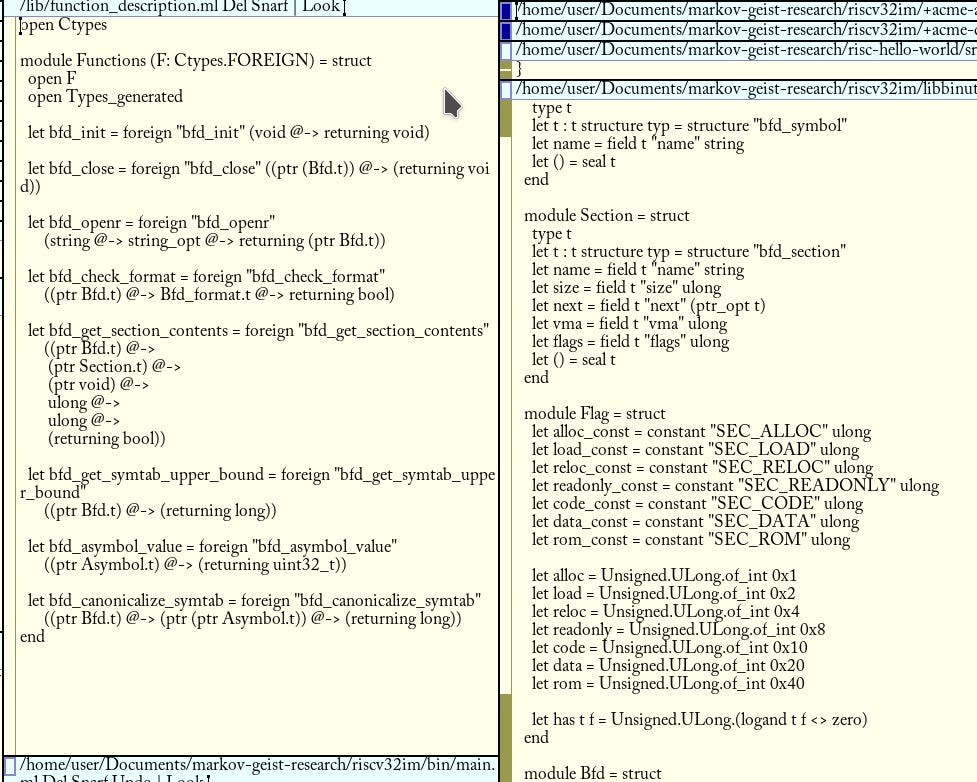
Using libffi and OCaml’s Ctypes makes this simple. This code essentially binds abstract types to definitions a C parser picks up, and we even manage the memory ourselves using the garbage collector and Bigarray with the C layout later when it asks for a memory pointer.

This lets us create downstream experiences from the bindings quite easily. The lower part is a simple application that reads sections and checks if the section exists for _start. We can use this to process the sections and symbols for the Rust code, which we then fill the gaps of to implement code like program functionality.
Implementing memory
Using the bindings, we can create a list of memory. This is an approach that doesn’t scale very well under performance (perhaps a btree, contiguous allocation, or a tree structure is better), but for our purposes of measuring and understanding the eventual implementation (and the nature of perhaps needing to store each section on-chain as a contract that we search to find) it works.
The simple type looks like such:

We need a function to construct our list of memory (and writeable, readable, and executable gaps):

Our memory needs a few functions to support accesses from within it:

The $$ infix operator is used by us to compose functions together in a Haskell style form. In OCaml, every function is “curryable”, where functions can be partially applied and made into new functions, as each function with multiple arguments is just a function taking one argument that’s composed to return another function with one argument, and so on.
This is the practice of partially applying a function like this simple math function that adds x, y, and z together:
# let a x y z = x + y + z;;
val a : int -> int -> int -> int = <fun>Returns another function that takes two arguments:
# a 123 456;;
- : int -> int = <fun>Which we can apply normally later:
# let b = a 123 456;;
val b : int -> int = <fun>
# b 123;;
- : int = 702First class functions are a neat tool we can use to build readable and reusable code. In our memory accesses, we scan the list to find the regions that we want to support.
Implementing Ethereum storage operations:
We implement some simple storage loading and storage writing operations. These are called into by the simulator when the user uses the environment calling operations.

Undoubtedly, a better approach is possible for this, probably using a driveby-style infix operator. We need to use the int32 type so can store this comfortably in our memory array later if needed.
We also implement a simple calldata type and a printing method:

We can be very flexible with the storage of this type since it’ll likely be immutable and just an array.
Implementing the simulator
We build a simulator record type that stores everything about our program.

We implement everything using a functional style, dropping into an imperative approach for our calldata and memory storage, for performance reasons. Even for our test tool we can’t support functional accesses over a bigarray quickly, and I don’t want to implement a write ahead log that we can use for this yet! Note that everything after the record field “[@default” is a hint for the syntax preprocessor which we use below, the “make” deriving preprocessor I use. The deriving fields include a generator some hypothesis testing and printing functions. In Rust, you might use:
#[derive(We implement registers:

And some gettors and settors:

Now that we’ve implemented the basis for our machine, we must implement the higher level datatypes of the decoded words:

We need a low level decoder now!
Implementing a decoder
Let’s create a record for a decoded word in a semi-decoded environment:

We implement some code to do decoding of the word to our in-between type:

There’s some off-screen masking and unpacking I won’t delve into here. I used riscv-opcodes from the RISC-V organisation as a reference alongside the manual to find the masks for every field inside a RISC-V decoded word. We can build a later stage of the decoding pipeline here that works on these decoded singleton tags.

These convert it to the higher level type we showed off in the decoding code. Following this operation, we can develop our lifted type.
Implementing the intermediate type
We can take the compiler output to do some pattern matching over the decoded type to our lifted representation:

This code unpacks the numbers contained within the word so we can convert them to our tagged type (that we saw earlier in the registers).
Building the simulator part 2
Now that we have our higher level type, we can start to pattern match over it and actually execute the code!

This code runs operations on each higher level type:
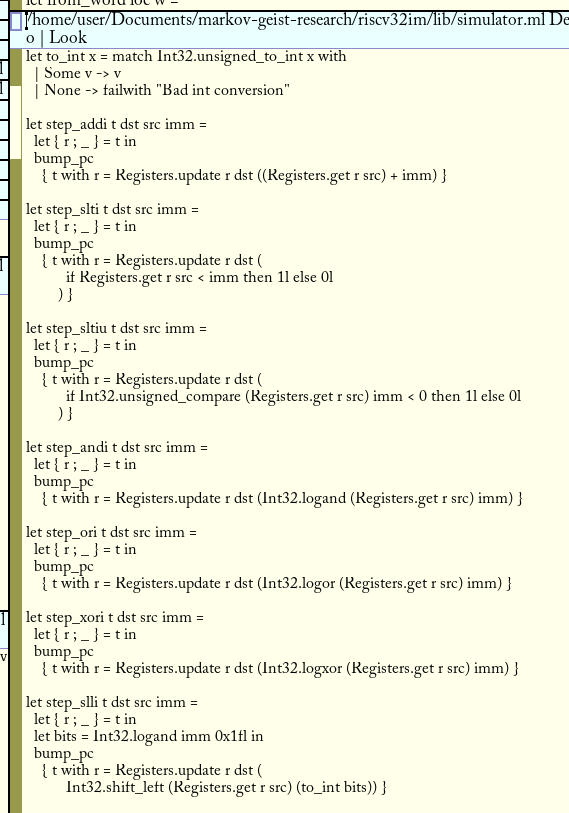
Which actually simulates the code in an entrypoint!

As a reminder, you can try this code at my repo. A lot of the work that went into this is being glossed over, including a rich encoding/decoding test to test the decoding (always implement twice!) and all of the generated testing code. I’m trying to focus on structure!
Interacting with Rust
This code lets us load and store words from the Ethereum storage:
let mut x = U256::from(100);
x += U256::from(123818);
let x_arr = x.to_be_bytes::<32>();
unsafe {
asm!(
"ecall",
in("a0") x_arr.as_ptr() as usize,
in("a1") x_arr.as_ptr() as usize,
in("a7") 1,
);
}
let mut b = [0u8; 32];
unsafe {
asm!(
"ecall",
in("a0") x_arr.as_ptr() as usize,
in("a1") b.as_ptr() as usize,
in("a7") 2,
);
}
let s = format!("{b:?}");
let ptr = s.as_ptr() as usize;
let len = s.len();
unsafe {
asm!(
"ecall",
in("a0") ptr,
in("a1") len,
in("a7") 0,
);
asm!("ebreak");
}
loop {}This silly program stores a unsigned Ethereum word (uint256) to memory, and reads it back to a separate slice, which it then prints using the logging environment call.
If we build and run it, we can see:
% dune build bin && ./_build/default/bin/main.exe /home/user/Documents/markov-geist-research/risc-hello-world/target/riscv32im-unknown-none-elf/debug/risc-hello-world
[0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 255, 255, 228, 14]Excellent! It seems we’re loading and storing correctly!
What’s next?
Stay tuned for part 2 on this, where we’ll show off how to use the contract entrypoint and storage features, and release the patched SDK. I’ll be progressively developing the devex on this project, and my hope is that we can use Stylus as the go-to environment for ALL smart contract development, especially if Ethereum begins support for RISC-V. This simulator is the first step to having simulation on Stylus WASM today, so we can build contracts everywhere tomorrow if needed.
You can start using the repo at
2) Levan
Who are you, and what do you do?
I’m really happy to feature Levan, the winner of the hackathon we hosted in Romania for Stylus! Super impressive programmer.

I am Levan, software engineer with 14+ years of experience, focused on Web3 for the last 6 years.
I started my journey in software development when I was 9 or 10, in Georgian IT center ‘Mziuri’ - I got into the school through a local math competition. I didn’t have a PC until I was 14 and I still remember how happy I was when I had my computer classes twice a week back then. My first programming language was Pascal - which, I still think is one of the best ways to introduce a child to programming. After a couple of years, when I finished learning fundamentals - I got selected in a gifted children’s program in the same IT center and I began a 5 years of extensive journey with algorithms, data structures, international and local competitions, etc. I believe that the knowledge and training that I got during those years made a huge impact on my career success. After I got my first personal computer (which, I still keep at home, btw) - I started learning things on my own as well - e.g. got my first Delphi programs written, learnt C++, later - PHP and C#..
I got my first job as a developer after I graduated school. I applied to become an intern in a local bank - ‘Liberty Bank’ as PHP developer and got hired. That internship and early years of my career boosted my love towards programming - I remember I was staying at the workplace for days to complete tasks and experiment with new things. After a couple of job changes I landed in one of the most interesting local jobs I had - Bureau of Troubled Assets - which was a local startup by three very experienced bankers. They trusted a 21 year old me to build their internal system from the ground up and for around 4 years I believe I did a good job. Those years were the best personal growth experience that I’ve had as a developer, as a person responsible for architecture and as a person overall - I made one of the most important decisions of my life during that period - I got married.
In 2017 I had my first interaction with crypto - I started mining Ethereum and Bitcoin. In 2017 I saw some ‘cloud mining’ platforms and created a similar one for the Georgian market, while I was still working at the Bureau of Troubled Assets. Founders were super impressed with the idea and helped me a lot with the organizational stuff. Then the market crashed and mining was not profitable anymore, so after the expiration of contracts we stopped that project.
In 2018 there were lots of changes in the Georgian financial market and I at the same time got a very interesting offer - it was time to grow. It was my first remote job as well - for two years I was responsible for building the backend of Sense Chat (EOS based e2e encrypted chat with social features). Then the project stopped, however - the CEO kept the team for another project - Libre, which is an Antelope-based scaling solution (Layer 2) for BTC. We recently launched a Loan platform which is already gaining some traction and hopefully it will become a successful project.
I believe that expanding my knowledge into different directions is key to my development and securing my and my families future and well-being. In 2022 me and a couple of my friends launched a local crypto on-ramp/off-ramp platform, currently serving around 40k users in Georgia. Besides that - I discovered that I love hackathons, I am good at them - and now I am trying to use hackathons to make new connections (that’s how I met Alex and now I am writing these lines) build out new products and potentially launch them.
What web3 ecosystems have you worked in?
I have worked with BNB Chain, ICP (currently in process of launching one of the projects that I built for ecosystem during the hackathon), worked with Antelope based ecosystems (Libre chain) - and still work on it on daily basis, worked a lot with Bitcoin (including Runes / Inscriptions)
What are your impressions of working with Stylus, good and bad?
Definitely good. Using Stylus allows me to write more complex (and expensive) logic in smart contracts, which – in the end, make my overall products better with simpler architecture. On the ‘nice-to-have’ side of things, I agree with Dragoș (we met each other at ETH Bucharest =) ) - more scaffolding tools would be nice. But hey - we can work on that ourselves and bring more value to the Stylus ecosystem.
What software do you use?
MacOS since 2019.
Editor: VSCode, Cursor.
I use Clickup for my day-to-day task management.
Termius for accessing my servers
iTerm as local terminal
What hardware do you use?
At the moment - Apple M3 Max with 64GB RAM. I upgraded from M1 max which I had for three years so.. next upgrade will be in 2027 (unless I break my current one)
How can we get in touch with you?
Say Hi, ping for potential collaborations - https://x.com/blockcraft-tech
What’s a piece of advice you’d give someone new to web3?
For anyone coming to Web3 - start thinking about the product, the value that you can create to attract new users. Web3 space desperately needs proper products.
Stylus Saturdays is brought to you by… the Arbitrum DAO! With a grant from the Fund the Stylus Sprint program. You can learn more about Arbitrum grants here: https://arbitrum.foundation/grants
Follow me on X: @baygeeth
Side note: I develop Superposition, a defi-first chain that pays you to use it. You can check our ecosystem of dapps out at https://superposition.so!
